
Legal Versus Ethical: Web Scraping Edition
Webbiquity
SEPTEMBER 7, 2021
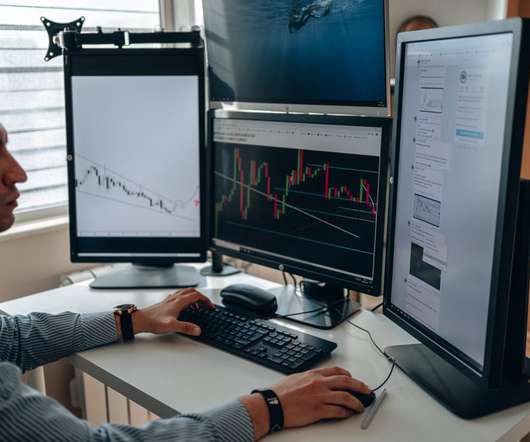
There is a huge quantity of data available on the Internet consisting of structured, unstructured, and semi-structured qualitative and quantitative data available in the form of web pages, databases, HTML tables, emails, blog posts, tweets, images, video, and so much more. Copyrighted material. Is the data copyrighted?





































Let's personalize your content